Global-and-Local Collaborative Learning for Co-Salient Object Detection
2 Nanyang Technological University, Singapore
3 A*STAR, Singapore
4 University of Chinese Academy of Sciences, Beijing, China
5 City University of Hong Kong, China
Abstract
The goal of co-salient object detection (CoSOD) is to discover salient objects that commonly appear in a query group containing two or more relevant images. Therefore, how to effectively extract inter-image correspondence is crucial for the CoSOD task. In this paper, we propose a global-and-local collaborative learning architecture, which includes a global correspondence modeling (GCM) and a local correspondence modeling (LCM) to capture comprehensive inter-image corresponding relationship among different images from the global and local perspectives. Firstly, we treat different images as different time slices and use 3D convolution to integrate all intra features intuitively, which can more fully extract the global group semantics. Secondly, we design a pairwise correlation transformation (PCT) to explore similarity correspondence between pairwise images and combine the multiple local pairwise correspondences to generate the local inter-image relationship. Thirdly, the inter-image relationships of the GCM and LCM are integrated through a global-and-local correspondence aggregation (GLA) module to explore more comprehensive inter-image collaboration cues. Finally, the intra- and inter-features are adaptively integrated by an intra-and-inter weighting fusion (AEWF) module to learn co-saliency features and predict the co-saliency map. The proposed GLNet is evaluated on three prevailing CoSOD benchmark datasets, demonstrating that our model trained on a small dataset (about 3k images) still outperforms eleven state-of-the-art competitors trained on some large datasets (about 8k~200k images).
Pipeline
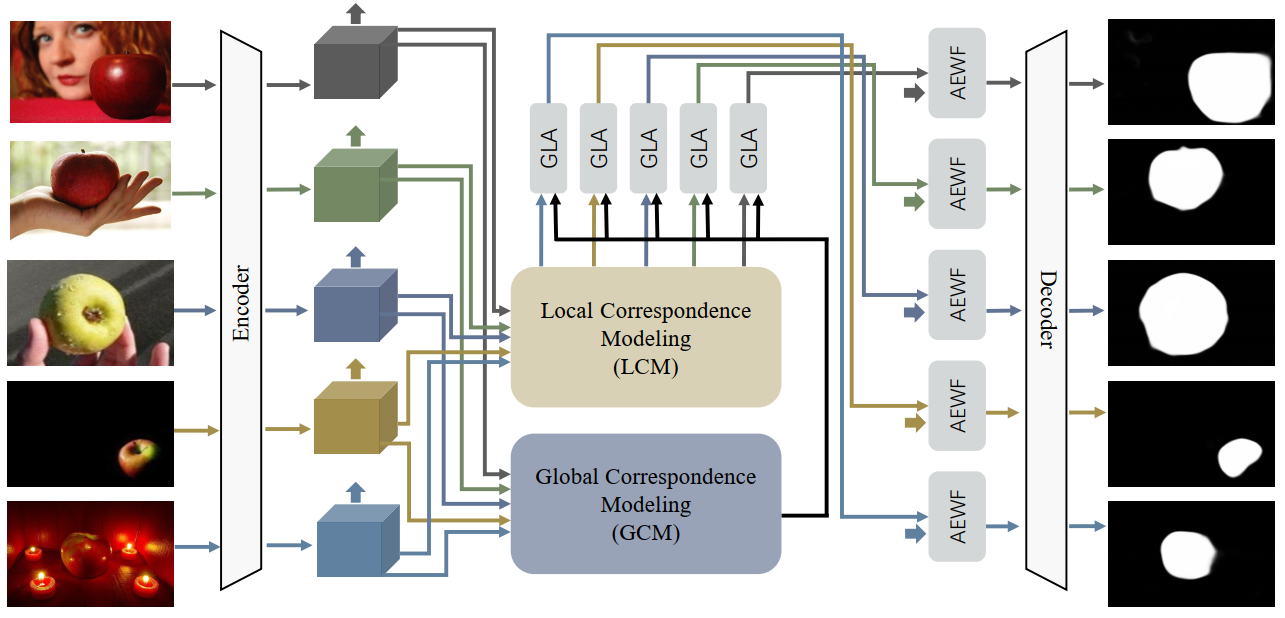
Architecture of GLNet. Given a query image group, we first obtain the deep intra features with a shared backbone feature extractor. A global correspondence modeling (GCM) module is applied to capture the global interactive information among multiple images, while a local correspondence modeling (LCM) module further collects the local interactive information between pairwise images. The global and local features are generated into inter features through a global-and-local correspondence aggregation (GLA) module. Then, the intra and inter features are further adaptively aggregated through an intra-and-inter weighting fusion (AEWF) module to learn co-saliency features. In the end, a multi-layer deconvolution is used to predict the full-resolution co-saliency maps M.
Highlights
We propose an end-to-end network for co-salient object detection, the core of which is to capture a more comprehensive inter-image relationship through the global-and-local collaborative learning. The global correspondence modeling module directly extracts the interactive information of multiple images intuitively, and the local correspondence modeling module defines the inter-image relationship through the form of multiple pairwise images.
For the global correspondence modeling, different images are regarded as different time dimensions, and thus 3D convolution is used instead of the usual 2D convolution to capture global group semantics.
For the local correspondence modeling, we design a pairwise correlation transformation to explore similarity correspondence between pairwise images. The two modules work together to learn more in-depth and comprehensive inter-image relationships.
Qualitative Evaluation

Visual comparisons of different methods. The first image group is axe, the second one is the pineapple, and the last one is white goose.
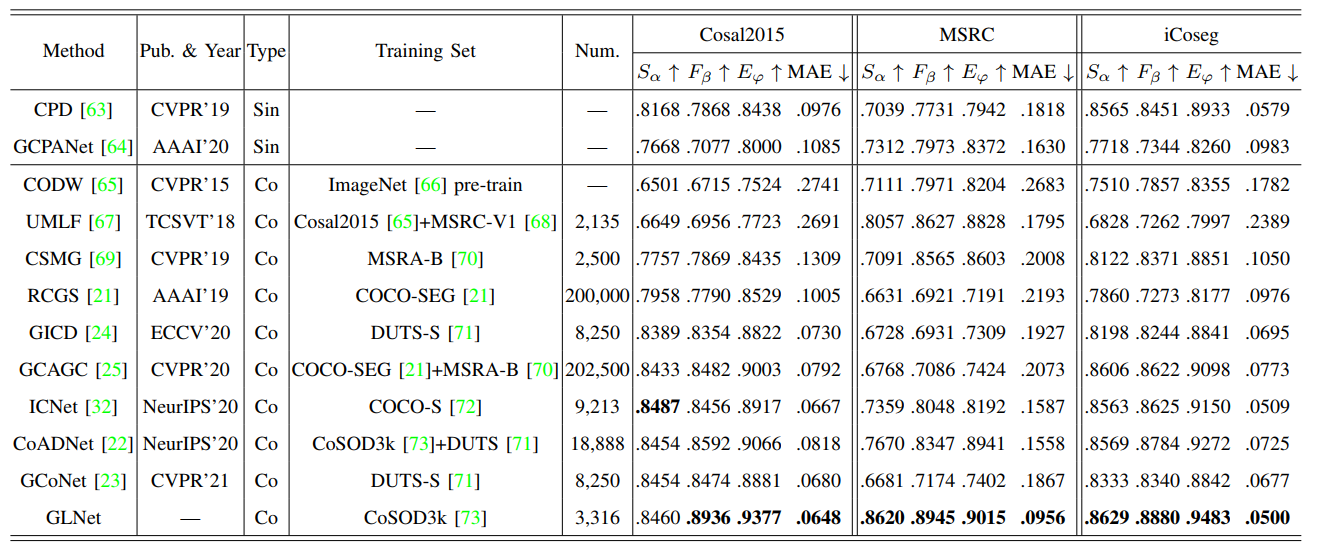
Quantitative Evaluation

Other works
Qijian Zhang, Runmin Cong, Junhui Hou, Chongyi Li, and Yao Zhao, CoADNet: Collaborative aggregation-and-distribution networks for co-salient object detection, Thirty-fourth Conference on Neural Information Processing Systems (NeurIPS), pp. 6959-6970, 2020. [Project Page]
Citation
@article{GLNet,
title={Global-and-local collaborative learning for co-Salient object detection},
author={Cong, Runmin and Yang, Ning and Li, Chongyi and Fu, Huazhu and Zhao, Yao and Huang, Qingming and Kwong, Sam},
journal={IEEE Transactions on Cybernetics},
year={2022},
publisher={IEEE}
}
Contact
If you have any questions, please contact Runmin Cong at rmcong@bjtu.edu.cn.